需求
- 监控多个项目的日志
- 统一集中化管理查看多个项目日志
- 多个项目的日志报错告警,当异常触发时能够及时通过短信、邮件等方式通知相关负责人员
- 建立日志可视化界面,使得日志分析更加便捷
- 其他自定义监控的实现
方案
现在我使用的是下面第三种方案,综合来讲会跟灵活并且占用资源少点。
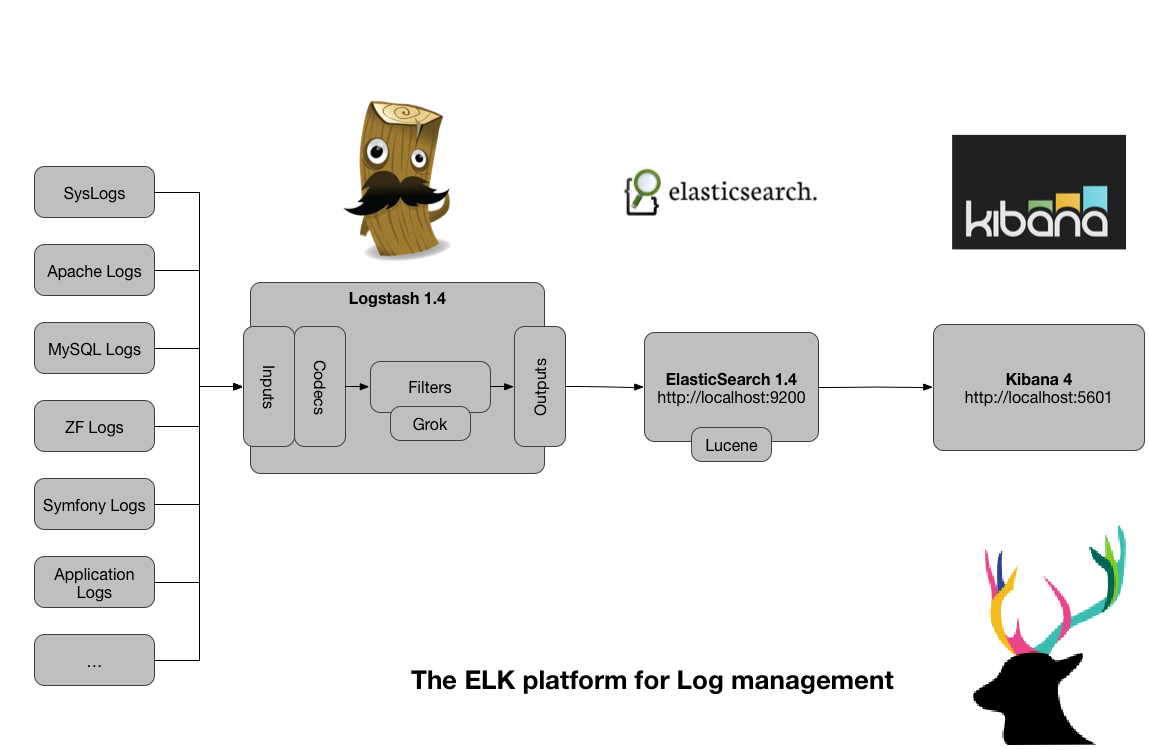
ELK(ES+Logstash+Kibana)
- Logstash(收集服务器上的日志文件)
- 保存到 ElasticSearch(搜索引擎)
- Kibana提供友好的web界面(从ElasticSearch读取数据进行展示)
#输出日志到logstash
log4j.appender.logstash=org.apache.log4j.net.SocketAppender
log4j.appender.logstash.RemoteHost=127.0.0.1
log4j.appender.logstash.port=4560
log4j.appender.logstash.ReconnectionDelay=60000
log4j.appender.logstash.LocationInfo=true
-
启动项目,log4j会把数据传输到logstash对应的端口
-
但是这里有点问题,我再使用6.3.X版本的时候这个方法并没有成功,查了网上的教程都是使用的2.X版本,而且官方已经提示logstash-input-log4j:This plugin is deprecated. It is recommended that you use filebeat to collect logs from log4j.已经废弃。
所以后期没有继续尝试解决了。
这里有一点需要说明,这里只说了log4j的情况,但是如果需要直接检测文件的变化,就需要在目标机器上也部署Logstash,这将是一个比较大的资源消耗。
[========]
EFK (ES+FileBeat+Kibana)
ELK(Elasticsearch, Logstash, Kibana)面临着这样的问题,Logstash虽然功能强大:支持许多的input/output plugin、强大的filter功能。但是确内存占用会非常大,并且需要依赖jdk。在Logstash 5.2+版本中,input plugin使用Log4j,必须使用filebeat,并且只支持log4j 1.x版本。了解到filebeat已经支持filter和不少的output plugin,所以fielbeat是更好的选择。
filebeat基于YAML,配置简单,格式明了
filebeat只是一个二进制文件,没有任何依赖,所以占用资源极少
- Filebeat(收集服务器上的日志文件)
- 保存到 ElasticSearch(搜索引擎)
- Kibana提供友好的web界面(从ElasticSearch读取数据进行展示)
-
安装下面的 ES+FileBeat+Kibana
-
修改监控的日志文件可以看到Filebeat控制台打印出
Harvester started for file: /home/tomcat/applogs/web.app.log
-
然后想到Kibana中查看相应的数据,使用kibana的DevTools可以查看到响应的索引,但是想在Index Pattern 中添加索引匹配就出现了一个问题:
Could not locate that index-pattern (id: false)
需要在Filebeat所在路径执行:
#重新载入索引模板
filebeat setup
如果执行这个命令出现一个FORBIDDEN/12/index read-only / allow delete (api)]的问题,需要在kibana的devtools中执行:
PUT .kibana/_settings
{
"index": {
"blocks": {
"read_only_allow_delete": "false"
}
}
}
- 执行setup之后会在kibana里面自动创建IndexPattern,之后在Discover中就可以选择
filebeat* 查看数据,并且可以在搜索框中搜索
这种部署看起来是最简便的,但是会遇到timestamp时区问题,在下面的方案中解决了。
[========]
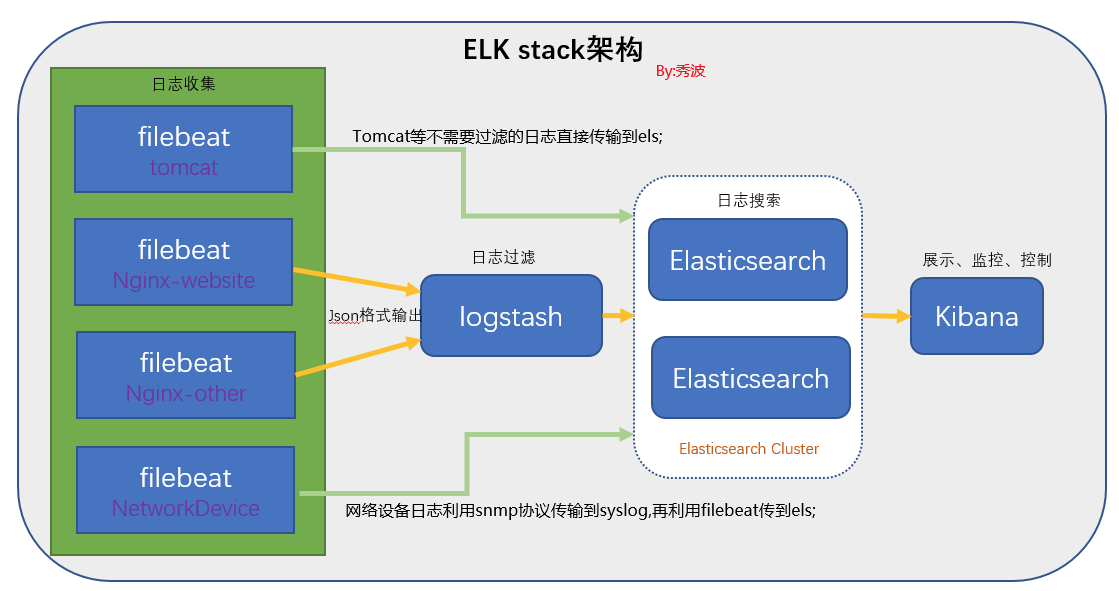
EFLK (ES+FileBeat+Logstash+Kibana)
这种方案是由前两种方案综合得来的,兼容了前两种的方便和强大的过滤功能。
- Filebeat(收集服务器上的日志文件)
- Logstash开启端口接受FileBeat的数据
- Logstash保存到 ElasticSearch(搜索引擎)
- Kibana提供友好的web界面(从ElasticSearch读取数据进行展示)
input{
beats {
port => 5000
}
}
output{
stdout{ codec => rubydebug }
elasticsearch {
hosts => "localhost:9200"
index => "t-server-%{+YYYY.MM.dd}"
document_type => "log4j_type"
user => your-username
password => your-password
}
}
- 修改Filebeat配置文件使其连接Logstash而不要连接ES
output.logstash:
# The Logstash hosts
hosts: ["xx.xx.xx.xx:5000"]
问题:
{
.....
"_source": {
"@timestamp": "2018-08-23T11:06:16.808Z",
....
"message": "2018-08-23 19:06:16,401 | INFO XXXXX",
...
}
}
可以看到上面的@timestamp和message对应的时间相差了8小时,原因是FileBeat的默认时间戳是0时区的时间,我们的log对应的时区是东8,那么如何解决呢?
在Logstash配置文件中加上配置Filter:
input{
...
}
output{
...
}
filter {
date {
match => ["message","UNIX_MS"]
target => "@timestamp"
}
ruby {
code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)"
}
ruby {
code => "event.set('@timestamp',event.get('timestamp'))"
}
mutate {
remove_field => ["timestamp"]
}
}
之后就正常了。但是这里注意,新的IndexPattern不能再选择@timestamp作为Time Filter field name了,这个时候的现象是在DevTools中能搜索出数据,但是在Discover这种不能显示数据。这是因为kibana依然再时间戳的基础上加了8小时的原因,所以最好的方案是不要修改timestamp,而是新建一个字段存储东8时间。
filter {
date {
match => ["message","UNIX_MS"]
target => "@timestamp"
}
ruby {
code => "event.set('timestamp_local', event.get('@timestamp').time.localtime + 8*60*60)"
}
}
只有在kibana中使用@timestamp来作为Time Filter field,但是在我们自己的查询可以使用timestamp_local来查询。
[========]
安装部分
注意:以下各个组件的版本号最好统一,否则可能出现各种问题
ES安装及配置
搜索、分析和存储您的数据。
Elasticsearch 是基于 JSON 的分布式搜索和分析引擎,专为实现水平扩展、高可用和管理便捷性而设计。
Elasticsearch 是一个分布式的 RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
新建用户
useradd elsearch
给elsearch用户权限
chown -R elsearch:elsearch elasticsearch
- 启动完成访问
IP:9200返回页面有json数据即可。
Kibana安装及配置
实现数据可视化
Kibana 让您能够可视化 Elasticsearch 中的数据并操作 Elastic Stack,因此您可以在这里解开任何疑问:例如,为何会在凌晨 2:00 被传呼,雨水会对季度数据造成怎样的影响。
-
下载:https://www.elastic.co/downloads/kibana
-
下载zip包到服务器,unzip解压即可
-
vim config/kibana.yml 修改配置文件,更换network.host: 0.0.0.0,便于外网访问。如果kibana和es在同一台机器可以不动别的配置,如果不在一台机器需要修改elasticsearch.url: "http://IP:9200
-
./bin/kibana &,可以使用root启动
-
启动完成访问IP:5601,页面会有一会的初始化时间,耐心等待,出现如下界面即可。
Logstash安装及配置
集中、转换和存储数据
Logstash 是动态数据收集管道,拥有可扩展的插件生态系统,能够与 Elasticsearch 产生强大的协同作用。
Logstash 是开源的服务器端数据处理管道,能够同时 从多个来源采集数据、转换数据,然后将数据发送到您最喜欢的 “存储库” 中。(我们的存储库当然是 Elasticsearch。)
input {
stdin { }
log4j {
host => "127.0.0.1"
port => 4560
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch{
hosts => ["localhost:9200"]
index => "log4j-%{+YYYY.MM.dd}"
document_type => "log4j_type"
}
}
-
./bin/logstash -f conf/log4j-es.conf 可开始监听
-
后台运行:nohup ./bin/logstash -f ./config/log4j_fliebeat.conf &
-
测试可以在控制台直接输入数据回车会有反馈,然后去kibana查看会有新的数据添加进去。
FileBeat安装及配置
filebeat是一个beat,它基于libbeat框架。
Filebeat是一个本地文件的日志数据搬运(shipper)。作为Agent安装,filebeat监视日志目录或指定的日志文件,并将它们转发给Elasticsearch或logstash进行索引。
启动filebeat时,它会启动一个或多个prospectors,查看为日志指定的本地路径。对于prospectors所在的每个日志文件,filebeat启动harvester。每个harvester为新内容读取单一日志文件,并将新日志发送到filebeat配置的输出。
filebeat.inputs:
type: log
enabled: true
paths:
- /home/tomcat/applogs/*.log
fields:
app-name: APP_NAME #多个应用用于区分来源
output.elasticsearch:
# Array of hosts to connect to.
hosts: ["IP:9200"]
关联Kibana:
# Kibana Host
# Scheme and port can be left out and will be set to the default (http and 5601)
# In case you specify and additional path, the scheme is required: http://localhost:5601/path
# IPv6 addresses should always be defined as: https://[2001:db8::1]:5601
host: "IP:5601"
./filebeat -e & -e 表示控制台输出
后台运行:nohup ./filebeat -e -c filebeat.yml >/dev/null 2>&1 &11
另外:
这样读进来的日志会按照单行进行采集,效果非常不好,所以开始使用multiline插件。
通过分析发现多行的匹配规则为只要不是以时间为开头的日志都归为上一行。
filebeat.inputs:
type: log
enabled: true
paths:
- /home/tomcat/applogs/*.log
fields:
app-name: APP_NAME #多个应用用于区分来源
multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
multiline.negate: true
multiline.match: after
[========]
参考:
http://www.cnblogs.com/xishuai/p/elk-logstash-filebeat.html
http://www.cnblogs.com/xishuai/p/spring-boot-log4j2-and-elk-logstash-filebeat.html
报警功能的扩展
ElastAlert
Elastalert是Yelp公司用python2写的一个报警框架(目前支持python2.6和2.7,不支持3.x),github地址为 https://github.com/Yelp/elastalert
工作方式
- 周期性轮询ES
- 数据传入elastalert规则引擎
- 规则匹配则转入elastalert告警器中
规则类型
- any:事件匹配指定filter
- change:指定字段在timeframe内发生值变动
- frequency:timeframe内发生几次以上事件
- flatline:timeframe内发生几次以下事件
- spike:事件频率升高或降低
- blacklist/whitelist:指定字段出现黑白名单
- new_term:指定字段出现新值
- cardinality:指定字段去重基数超出或低于一个阈值
参考:
https://anjia0532.github.io/2017/02/14/elasticsearch-elastalert/
自己写一个吧
加到crontab 里面就可以了
crontab -e
*/2 * * * * python /home/LogErrorAlert.py >> /home/LogErrorAlert.py.log 2>&1
# -*- coding: utf-8 -*-
# */2 * * * * python /home/LogErrorAlert.py >> /home/LogErrorAlert.py.log 2>&1
import os
import locale
from email import parser
import email
import string
import time
import datetime
import smtplib
import poplib
from email.header import Header
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.header import decode_header
import sys
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
mail_host = "smtp.exmail.qq.com"
mail_pop_host = "pop.exmail.qq.com"
mail_user = "XXXXXX"
mail_pass = "XXXXXX"
receivers = ['XXXXX']
# 确定运行环境的encoding
__g_codeset = sys.getdefaultencoding()
if "ascii" == __g_codeset:
__g_codeset = locale.getdefaultlocale()[1]
def sendmail(receivers, content):
message = MIMEMultipart()
text = MIMEText(content, 'html', 'utf-8')
message.attach(text)
message['From'] = mail_user
message['To'] = Header(",".join(receivers), 'utf-8')
subject = '!!!ERROR ALERT!!!'
message['Subject'] = Header(subject, 'utf-8')
try:
smtpObj = smtplib.SMTP()
smtpObj.connect(mail_host, 25)
smtpObj.login(mail_user, mail_pass)
smtpObj.sendmail(mail_user, receivers, message.as_string())
except smtplib.SMTPException:
print 'Send email failed'
class ElasticObj:
def __init__(self, index_name, index_type, ip ="127.0.0.1"):
'''
:param index_name: 索引名称
:param index_type: 索引类型
'''
self.index_name =index_name
self.index_type = index_type
# 无用户名密码状态
#self.es = Elasticsearch([ip])
#用户名密码状态
self.es = Elasticsearch([ip],http_auth=('elastic', 'password'),port=9200)
def Get_Data_By_Body(self, time_str):
doc = {
"query" : {
"bool" : {
"must" : [
{
"match_phrase" : {
"message" : {
"query" : "ERROR",
"slop" : 0,
"boost" : 1.0
}
}
}
],
"filter" : {
"range" : {
"timestamp_local" : {
"gte": time_str
}
}
}
}
},
"sort": [
{
"timestamp_local": {
"order": "desc"
}
}
]
}
_searched = self.es.search(index=self.index_name, doc_type=self.index_type, body=doc)
flag = False
content = 'Error Messages are as follows:</br></br></br>'
for hit in _searched['hits']['hits']:
flag = True
# print hit['_source']
content = content + "Time: " + hit['_source']['timestamp_local'] + "</br>"
content = content + "Host: "+ hit['_source']['host']['name'] + "</br>"
content = content + "Message: </br>" + hit['_source']['message'].replace('\n','</br>').replace('\t',' ') + "</br></br>"
content = content + "==============================================================="
if flag:
sendmail(receivers, content)
print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()),", Getting Errors in two minute...."
time_before = time.localtime(time.mktime(time.localtime()) - 2 * 60)
time_str = time.strftime("%Y-%m-%dT%H:%M:00.000Z", time_before)
obj =ElasticObj("logstash*", "log4j_type", ip ="XXXXXXX")
#obj.Get_Data_By_Body("2018-08-24T09:03:16.000Z")
obj.Get_Data_By_Body(time_str)
完。
补充:
由于ES和jenkins在同一台机器上,jenkins出现过一次错误导致日志文件短时间内达到十几个G,磁盘爆满。之后删除文件并重启ES,Logstash报错:
retrying failed action with response code: 403 ({"type"=>"cluster_block_exception", "reason"=>"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"})
解决:
Once you hit the floodstage watermark (95% by default), you must manually release the index lock — see https://www.elastic.co/guide/en/elasticsearch/reference/6.2/disk-allocator.html 550. The following will do the trick, which you need to run for every affected index:
PUT /your-index/_settings
{
"index.blocks.read_only_allow_delete": null
}
PS: Please properly format your code; it's pretty hard to read otherwise.